Wanted to do a quick post on PDF analysis. This will be a 2 part post, I don’t have time to finish it this week because Shmoocon is this weekend and I need to do other things :) The sample I'm using can be found here.
Probably the easiest and fastest thing to do is to run the PDF in a VM with acrobat reader and whatever tools you use to monitor system changes and just snag whatever dropped files you get to analyze. If that doesn’t work, and you have a throwaway system lying around that you can re-image later, you could just open the PDF in acrobat on a real physical machine and collect your files.
But if that fails, you don’t have the vulnerable version of acrobat reader installed, or whatever, you just don’t seem to get any dropped files, we can still try and get something to analyze. The first thing I do with a PDF typically is open it in 010 editor, and using Didier Stevens file format template found here, take a look at it and see what info we can get. A few things I immediately look for are, multiple "%EOF", or "/Javascript" tags, or "/EmbeddedFile", and I usually start by looking at the objects that are the largest in size. Kinda like this:

Also, if we select that last struct thats defined in 010 as a PDFXref, up top you will see one "%EOF" and if you scroll to the very bottom (about 164700 bytes on down) then we will see another "%EOF". Looks fishy eh :) Probably embedded file(s). At this point, your fastest route would probably be to to look shortly after the first "%EOF" for an 'M' and see if the next byte could be XOR'd with something to get a 'Z', then track down the PE section and try to dig the binary out manually. If you can do that, you can save yourself the following steps. I took a glance, and I noticed all incrementing and decrementing bytes:
Those are probably NULLs, so it looked like an incrementing / decrementing 2 byte key, but I fiddled with it for an hour or so and my un-XOR'd version certainly wasnt a valid PE file so I decided to analyze the shellcode instead. I haven't analyzed the shellcode yet, so it probably is still some simple XOR encryption.
So lets use yet another useful tool by Didier Stevens, pdf-parser, and it can be found here. If we run "pdf-parser.py --stats xxxxxxxx.pdf" on the file, it looks like object 1 has an embedded file:
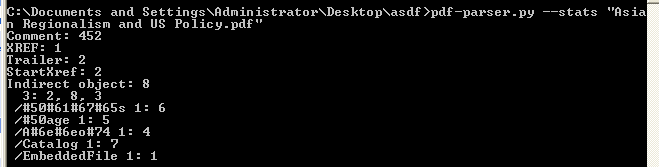
So lets get a little more info on that object by running "pdf-parser.py --object 1 --raw xxxxxxxx.pdf" and we see this is object contains a stream of compressed data:

Getting warmer :) So lets inspect this fishy ass object by using the --filter flag and send the output to an xml file like so:

and if we open this up with notepad++ we see the following:

Looks like base64 encoded shellcode to me :) lets decode it in either notepad++ or copy it over to 010, they both can do it for us. I prefer 010, so copy everything between quotes after that "sBase=" tag, so starting at "SUkq..." down to "...AAC=" and paste it into a new file in 010. You should be here:

After you have it in the new file, highlight everything and run the DecodeBase64 script on it, and then switch to the hex view and we should see this:

Scrolling through, it looks like a NOP sled followed by some shellcode doesnt it? now you can save this new binary file and in IDA you can open it and take a look, or use a tool that will convert the hex to a binary we could debug. Thats what we'll do next post.
If you're pressed for tools Python also can do the base64 decode with something like:
import base64, sys; base64.decode(open("input.txt", "rb"), open("output.hex", "wb"))
where you saved "SUkq..." down to "...AAC=" in a text file in your current directory and named it "input.txt".
Thanks to Didier for his blog thats chock full of useful information, check it out if you haven't already.
bye
No comments:
Post a Comment